
围绕 Anki 构建知识体系的三种方法|学习骇客
2025 / 9 / 16
构建知识体系一直是大家的强需求,尽管我在多年前翻译《卡片笔记写作法》这本书时就专门写过文章,但很多同学仍然不知道具体方法。

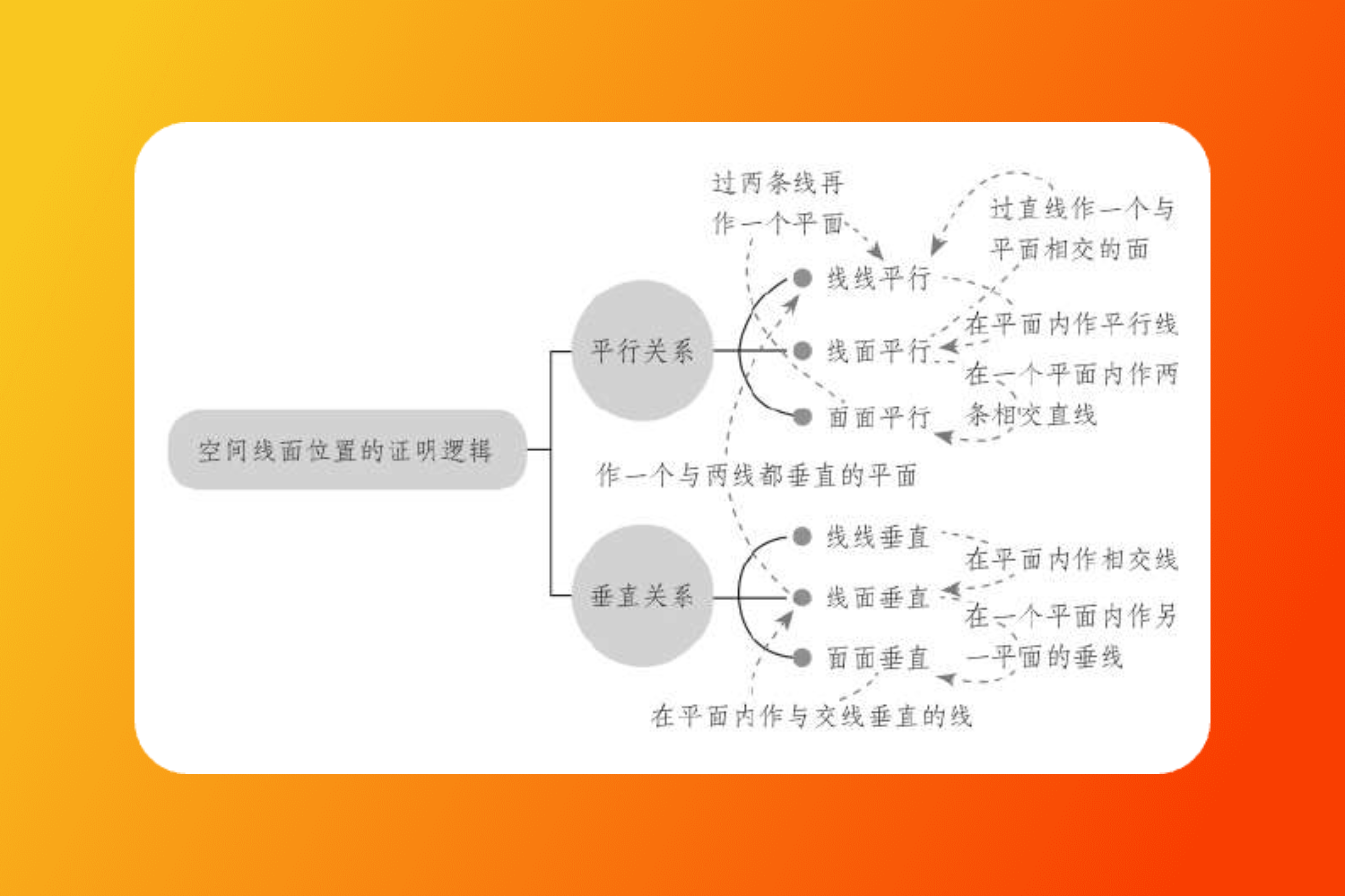
刚好,最近读《应试数学》时也读到了类似的论述,并且与多年前的思路不谋而合,都是分成了“自下而上”和“自上而下”两种策略。

再结合这些年以来的实践经验和实践成果,借助 flomo App、Get App、Schema Weaver 插件和 WeRead to Anki 插件等新工具,具体谈一谈围绕 Anki 构建知识体系的方法。
方法一 自下而上
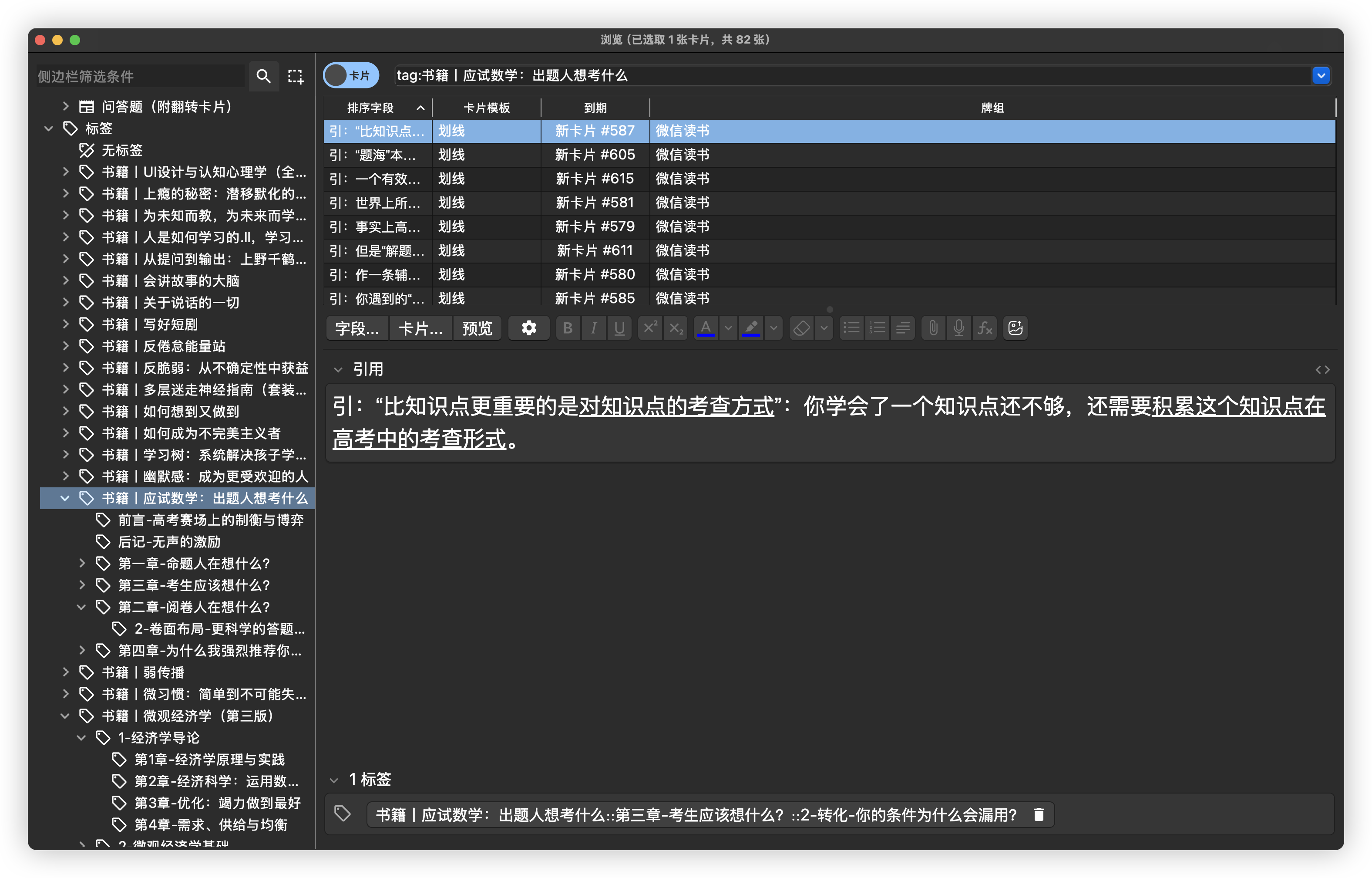
先在 Anki 里记卡片笔记,在记的过程中或记完后停下来梳理主题,从笔记里分析包含的主题,然后组织相关主题得到结构,即自下而上的方式。
今年上半年在学习动画软件 Rive 时,我先在几个月里记了约 1000 张卡片笔记,然后从笔记里梳理出一级主题,并在每个一级主题下整理出二级和一些三级主题,通过多层主题搭建起结构体系。
如果记完笔记后仍然没有关于主题的思路,可能需要反思一下是不是自己压根就没有围绕主题进行学习,或者在复习过程中只顾着当前笔记,并没有由此及彼地进行联系,又或者可能对笔记还不熟悉。总之,只要学习是围绕主题进行的,在复习过程中也进行广泛思考了,在复习到相对熟悉后自然就会在头脑中涌现出某些主题,最后通过主题构建起结构。
梳理的过程也不是一蹴而就、一劳永逸的。我们的思考其实来自新知识和旧知识的碰撞,当你学习了新知识或长时记忆中的旧知识得到了巩固,再复习同样的笔记时,往往就会有不一样的想法。所以,建立结构体系是一个长期迭代的过程。
只有积累,没有整理也不行。很多同学抱怨 Anki 的碎片化,但这其实不是卡片的问题,而是我们自己缺少定期总结的习惯。当你联想到某些相关知识,或者能够就某个主题展开说说之后,就应该及时记录一张总结性质的卡片。当然,现在也可以通过 Schema Weaver 插件将 Anki 的多级标签以结构化的形式呈现出来了。

方法二 自上而下
根据课程或考试大纲的目录设计多级标签,就得到了自上而下的结构。
通过 WeRead to Anki 插件和 Mubu to Anki 插件导入 Anki 的笔记,都能根据微信读书中的书籍目录和幕布里的大纲结构自动在 Anki 里创建完整的多级标签,通过 Schema Weaver 插件在 Anki 里呈现如下图所示的效果(插件地址 )。
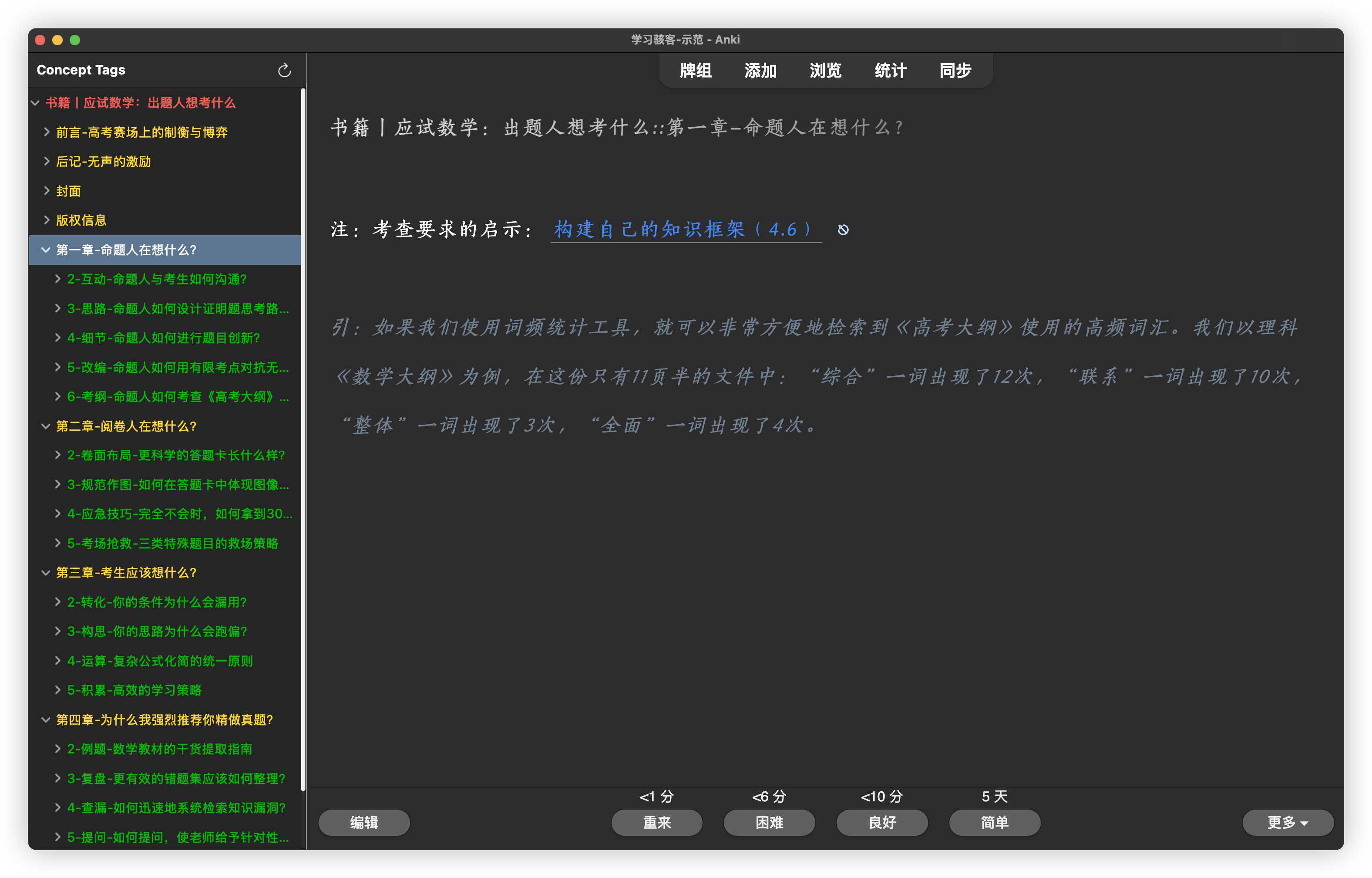
如果你只用 Anki 记笔记,也可以提前添加一条占位笔记,在该笔记里添加所在书籍的多级目录,例如从“第01章::第01节”到“第18章第06节”,之后再记笔记时就可以通过只输入几个字自动匹配。这样不仅省事,还能避免输入错误。
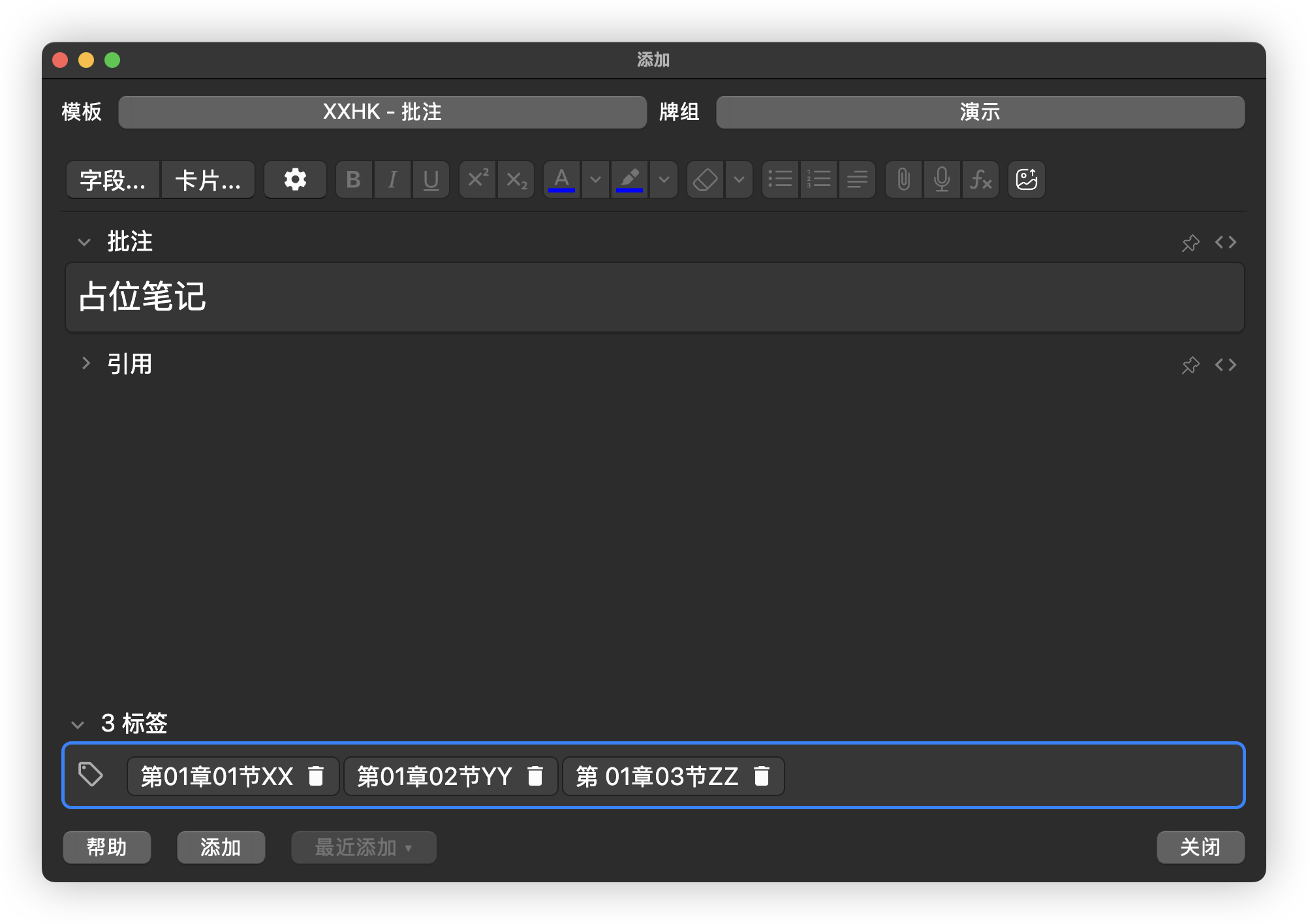
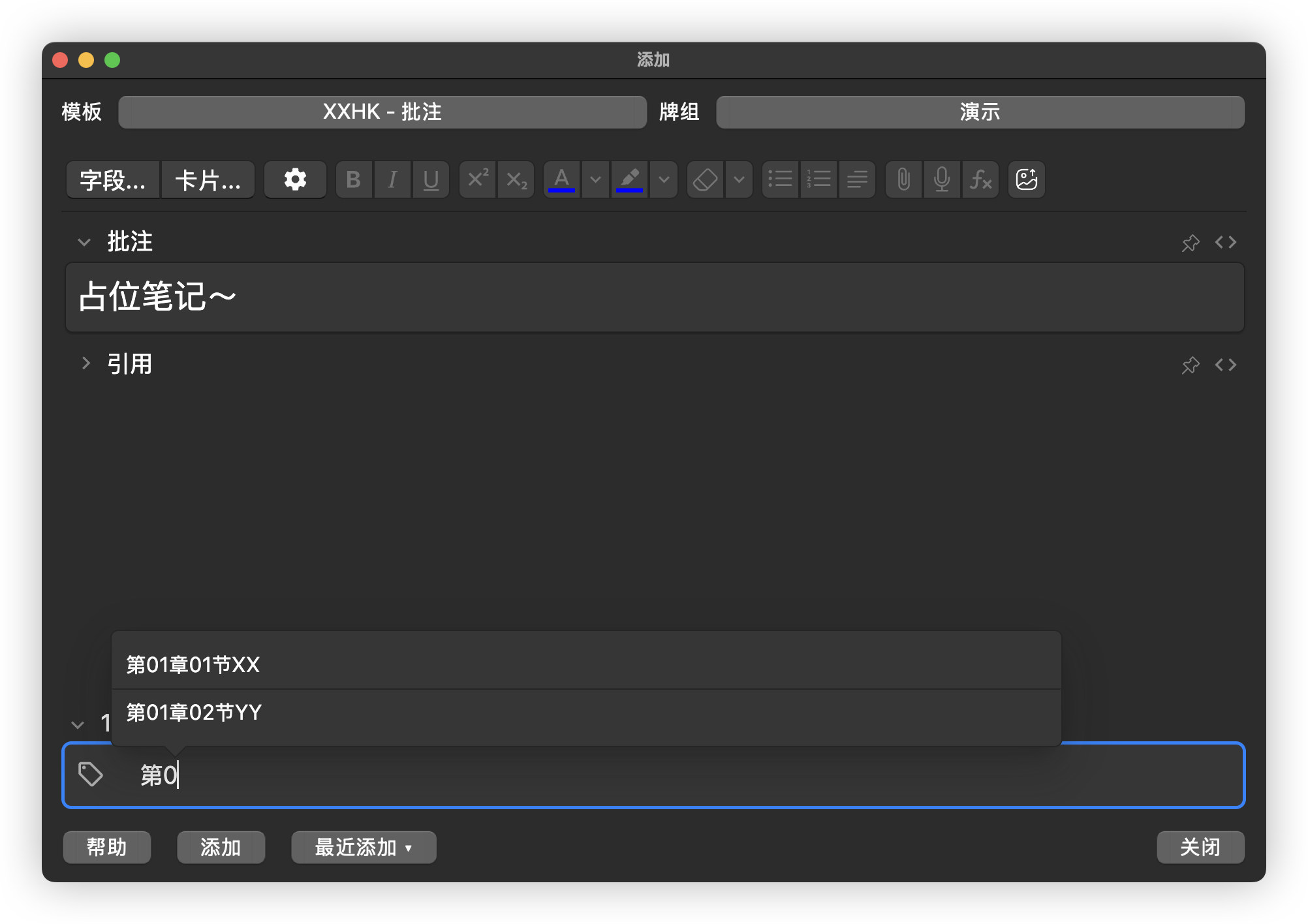
处理纸质书目录更简单的方法是拍下书籍目录的照片后发给 DeepSeek,让它整理成 Markdown 格式,然后粘贴到幕布笔记里,最后批量调整层级关系。如果只用幕布,那么幕布里有书籍目录,如果导入 Anki,还能自动形成多级标签形式的结构。
方法三 人机协同
自己记高质量的卡片笔记,利用 AI 功能进行总结,代表性的卡片笔记工具 flomo 和 Get 都有 AI 总结的相关功能。
如下图所示,我用 flomo 记与工作相关的一阶和二阶思考成果,用 Get 记与生活相关的三阶及更多思考成果。当我需要解决生活困扰时,就在 Get 里提问。当我需要工作参考时,就到 flomo 里洞察。flomo 的洞察功能和 Get 的提问功能都已经达到了可常态化使用的水平,并且早已经成为我的日常习惯。
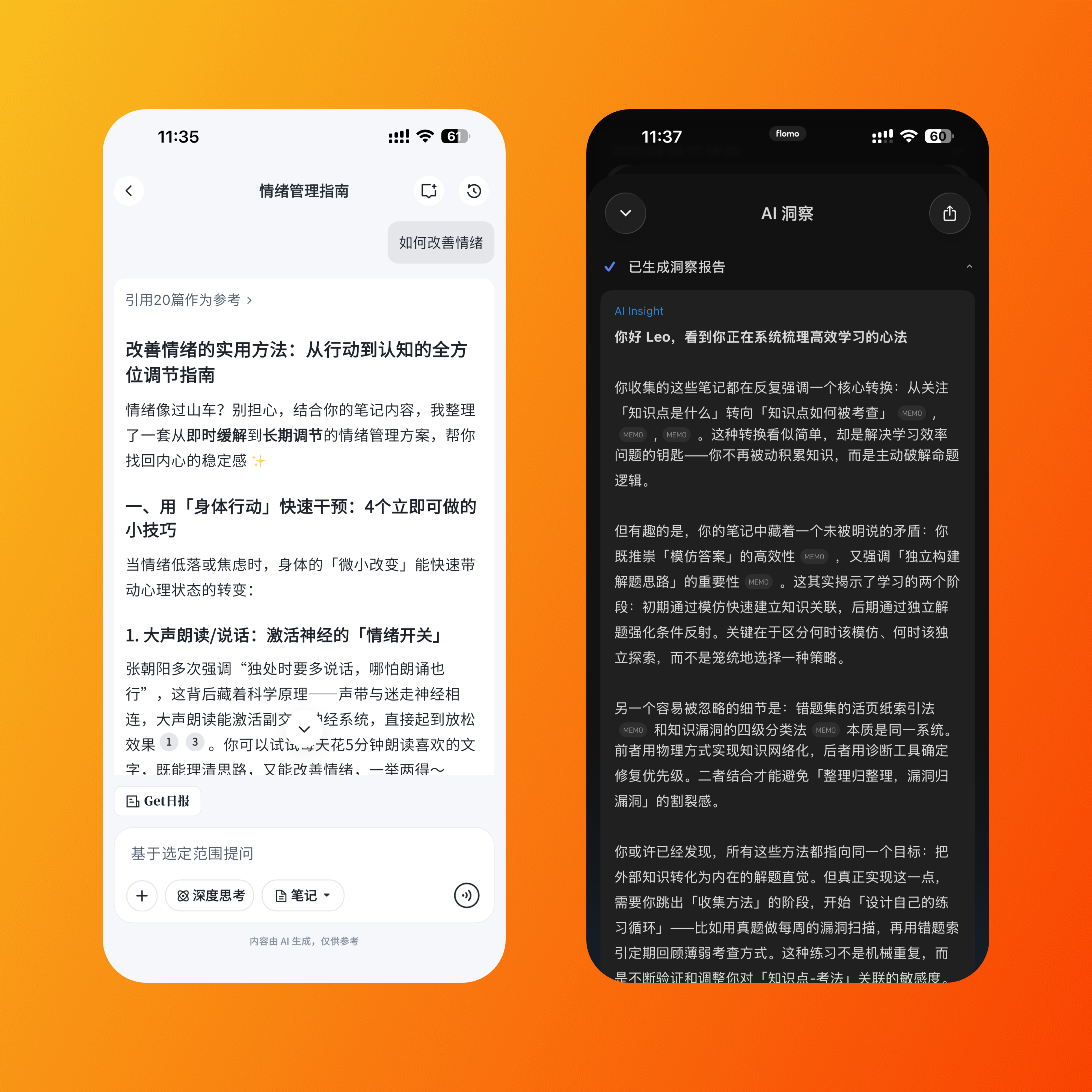
随着内容的更新,AI 的回答也会基于新的内容自动更新,省去了手动整理的麻烦。
但是,有了自动整理的方式并不意味着可以省略 Anki 里的手动构建。因为 AI 的答案是不固定的,很多时候我们仍然需要确定的组织方式。只有手动创建的结构也不好,那就失去了生成更多创意想法的机会。因此,方法一、方法二与方法三是互补关系。
在搭建人机协同的知识体系时,有几点需要注意。应坚持以卡片形式输入,因为卡片的去中心化组织方式更有利于重组。此外,大语言模型仍然存在上下文腐烂(Context Rot)现象,如果上下文的长度增加,模型的输出质量和推理能力会逐步下降。要坚持切己体察,通过笔记记下知识对自己的价值、与自己的关系,不然就只能得到一个可有可无的通用知识库。最后,需使用自己在 Anki 里复习过的笔记,搜索时能看得懂,应用时能用得上。