
WebClipper for Anki 进阶用法:正则替换
2024 / 11 / 22
WebClipper for Anki - XXHK 插件从 2.8 版开始支持替换,包括普通的替换和正则替换,这将大大增强对某些特殊网页、特殊样式的兼容。点击浏览器右上角的插件图标,即可进入设置页面。
如果不了解正则 ,可以通过 ChatGPT 学习,例如,如何匹配删除以X开头的句字,如何替换包含X的单词为Y⋯。或者这样问“这是⋯原始内容,我希望通过正则替换只保留⋯内容”,通常就能直接得到匹配的正则替换的规则。
这样的好处在于我们可以根据当前摘录的需要,即时地、个性化地完善摘录样式。这比从插件设计层面解决更简单,况且再怎么适配也不可能兼容所有网页。
⚠️ 注意:如果是常用的替换规则,尽量在别处备份好,防止插件卸载或更新导致丢失,例如添加到输入法的常用语里;如果是临时的替换规则,别忘了在摘录完之后删除替换,以免对其他内容造成期待之外的替换。
场景 1:普通替换(替换/还原/强调)
原网页上有一些翻译错误,需要在摘录后纠正,例如“Screen Studio”被翻译成“屏幕录制工作室”,我们可以通过替换将“屏幕录制工作室”替换成“Screen Studio”(专有名词保持原形)。
原网页上的措辞不统一,可以在摘录时通过替换变成一致性表述,例如将“长期记忆”替换成“长时记忆”,与笔记里已有的“长时记忆”保持一致。
原网页上的某些内容需要在摘录后特殊标记,例如将“AI”替换成“⚡AI”。
场景 2:移除多余内容
从推特(x.com)摘录的内容,如果未经处理,会包含大量的冗余代码,不仅样式乱了,也增加了笔记的体积。通过替换(正则),我们可以只保留自己需要的部分。

替换:/[\s\S]*?(<span class="css-1jxf684 r-bcqeeo r-1ttztb7 r-qvutc0 r-poiln3"[^>]*>.*?<\/span>)[\s\S]*?(<img alt="图像" draggable="true" src="[^"]*"[^>]*>)[\s\S]*?(<a href="https:\/\/x\.com[^>]*>.*?<\/a>)/ 替换为:$1<br>$2<br>$3
原文的样式:
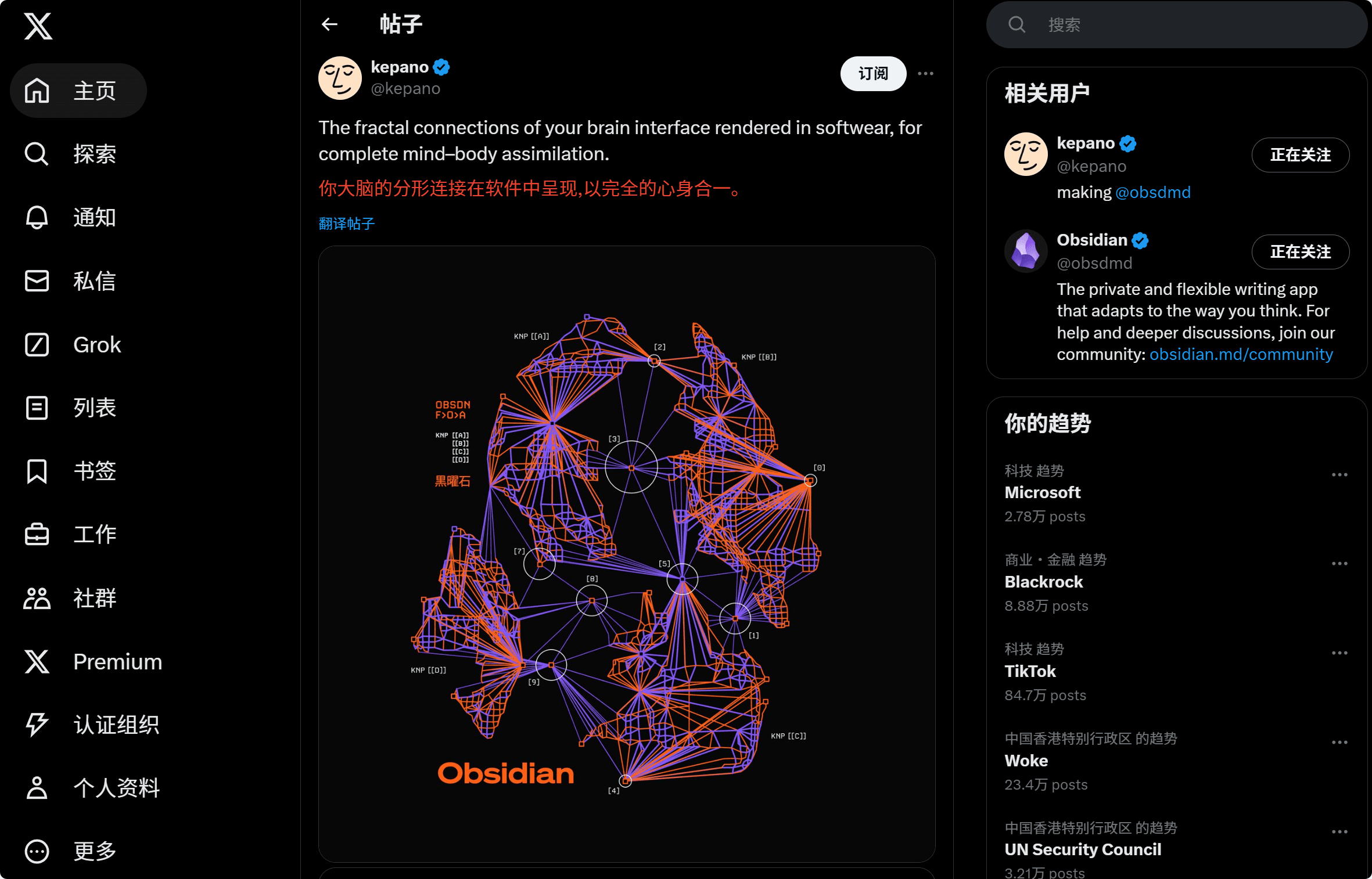
替换前的摘录:

替换后的摘录:
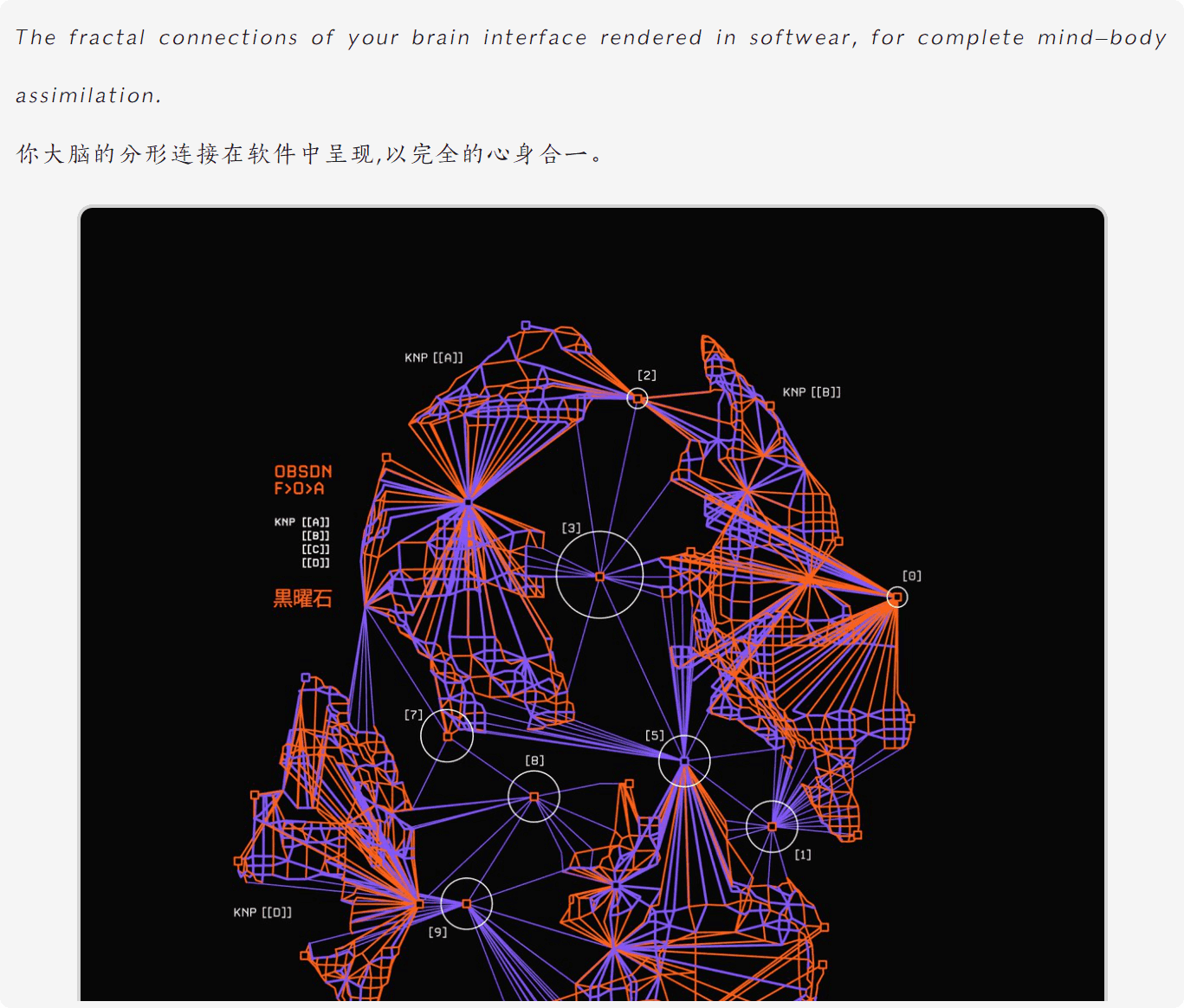
场景 3 补充缺失内容
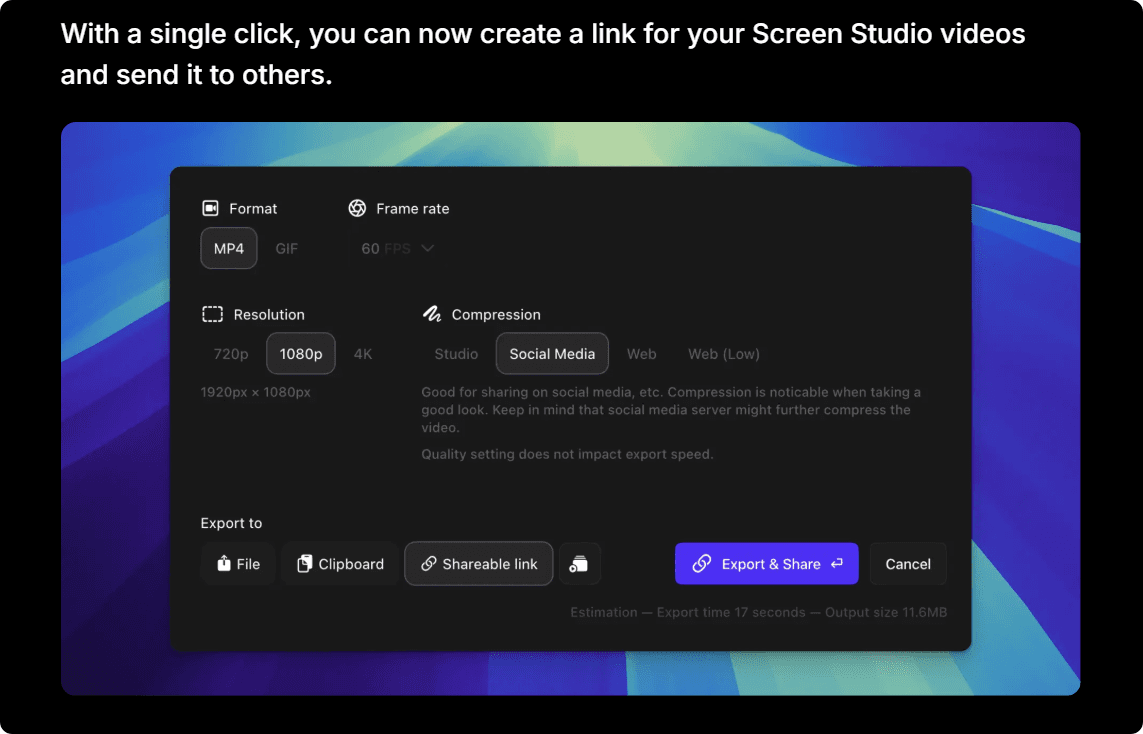
有些网页的图片地址使用了相对路径,例如 Screen Studio 页面的图片地址。网页会根据图片所在的路径,自动补全前面的 https://screen.studio 部分,因此在网页上可以正常显示。
<img src="/_next/⋯">
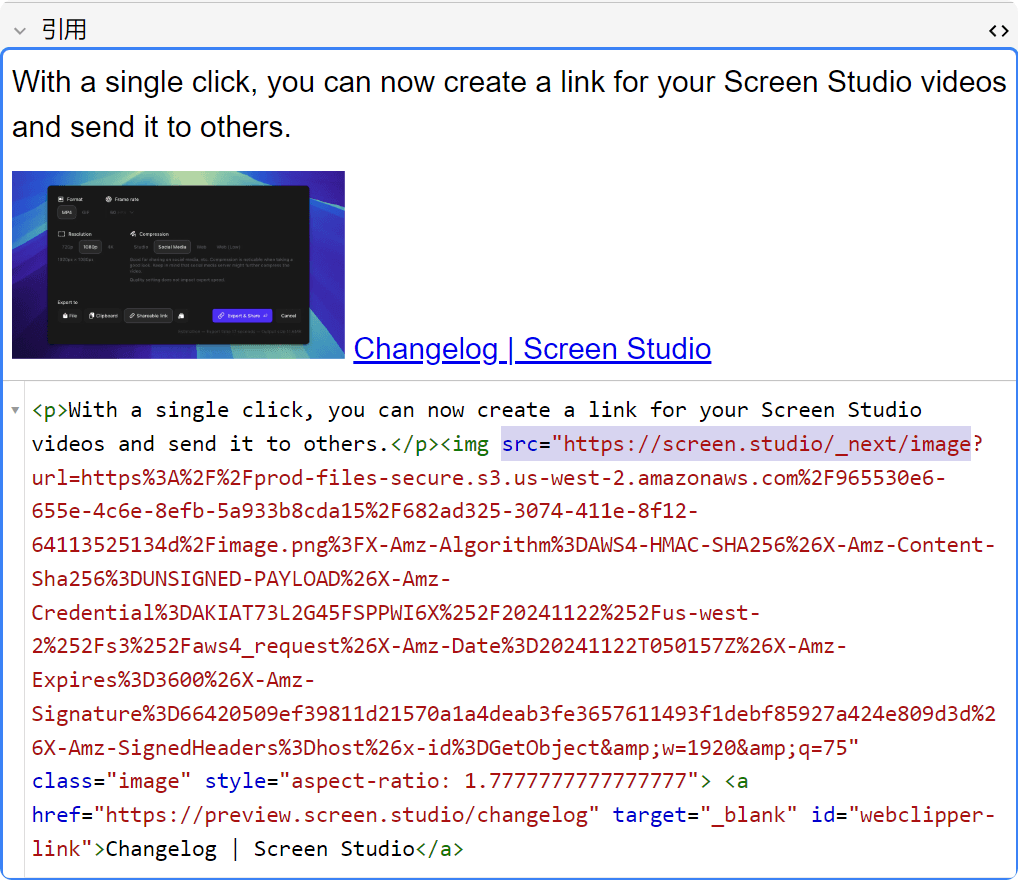
但是这样的相对路径脱离了服务器、来到本地 Anki 后,却无法自动补全前面省略的地址,就导致在 Anki 里无法显示。
不过,好在这种变化有规律,我们可以通过普通的替换实现补全:

替换:<img src="/_next/ 替换为:<img src="https://screen.studio/_next/
这是原文效果:
这是替换前的 Anki 效果:

这是替换后的 Anki 效果:
在测试过程中,我还发现一些让人无语的现象。有的网站的网页为图片混用了绝对路径和相对路径两种样式,如果你在替换时发现同一个网站的网页有些能正常替换而另一些不能,可能就是这个原因,需要通过查看 Anki 里的 HTML 模式了解它们之间的源码的差异,然后在替换 X 时避免误替换了 Y。通常二者之间只要存在差异,就可以区别性替换。